Do Video Language Models Really Know Where to Look?
Diagnosing Attention Failures in Video Language Models
Anonymous Submission
Case study for RQ1: Are vision encoders robust to interrogative or ambiguous linguistic cues?
Case Study 1

Answer: Wrestle
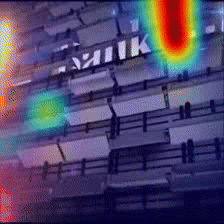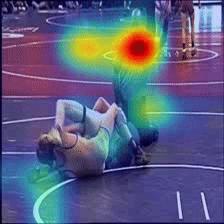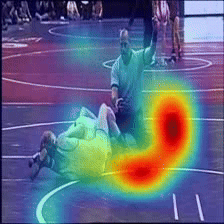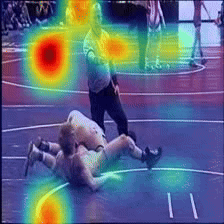
Question: What are two people doing?
Case Study 2
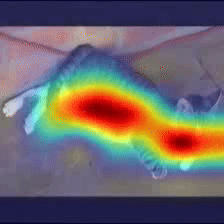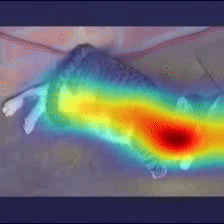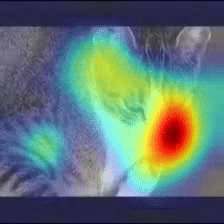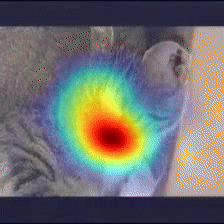
Answer: Cat

Question: What is on the ground?
Example for Appendix B.1: Video clips and questions of samples that are blue-dominant and white-dominant
Examples of samples with consistently correct (blue)
Question: How would you describe the efficiency and effectiveness of c's actions while performing tasks related to the main activity, considering the sequence and steps throughout the video?
Question: Summarize the primary technique used by c to create and refine the flower pot. how did c utilize the tools and materials available to her?
Examples of samples with consistently incorrect (white)
Question: What is the overall objective of the woman's actions throughout the video and how do her actions contribute to that objective?
Question: How would you concisely describe the overall process that c undertakes in order to prepare the plantain flower throughout this video?